
/
Oct 17, 2024
How Meta Uses LLMs to Improve Incident Response (and how you can too)
How Meta Uses LLMs to Improve Incident Response (and how you can too)
Meta used LLMs to root cause incidents with 42% accuracy. Here's how they did it and how you can do it too.
Meta used LLMs to root cause incidents with 42% accuracy. Here's how they did it and how you can do it too.

Wilson Spearman
Co-founder of Parity
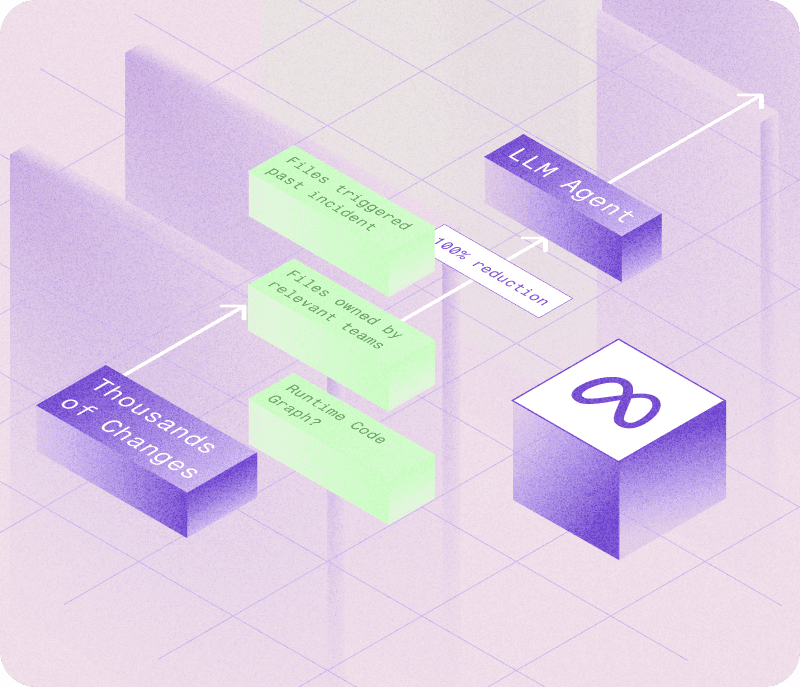
In June, Meta released an article titled Leveraging AI for efficient incident response on their engineering blog. In this article, engineers outline how they leveraged large language models to improve Meta's incident response capabilities. The headline metric from this report: Meta was able to use LLMs to successfully root cause incidents with 42% accuracy in their web monorepo. This means that nearly half the time, the mean time to resolution (MTTR) can potentially be reduced from hours to seconds. Seeing one of the largest and most complex engineering organizations in the world use generative AI for incident response so successfully gives us hope that we can bring the same benefit to all engineering teams with Parity. Let's dive into how Meta accomplished these results and what we can learn from it.
Meta's Incident Management at Scale
It can be hard to appreciate the scale and velocity of code changes at a company the size of Meta. They are shipping thousands of changes per day almost entirely within a single monorepo. Meta literally re-engineered Mercurial to keep up with the speed at which their codebase was growing (really fun read and nugget of open source history). At this scale, investigating outages becomes a massive undertaking. "Hey did anyone ship anything recently" in #engineering probably doesn't cut it as a response process.
Meta has invested in sophisticated incident response tools to make the life of on-call engineers easier. All of that tooling is built to solve the same problem any engineer at any organization aims to solve: what's going wrong, why is it going wrong, and how do we fix it. Generative AI has clear potential to improve MTTR and incident management processes across the board, and Meta charts one of the potential paths to doing so.
Meta's Approach to LLMs for Incident Response
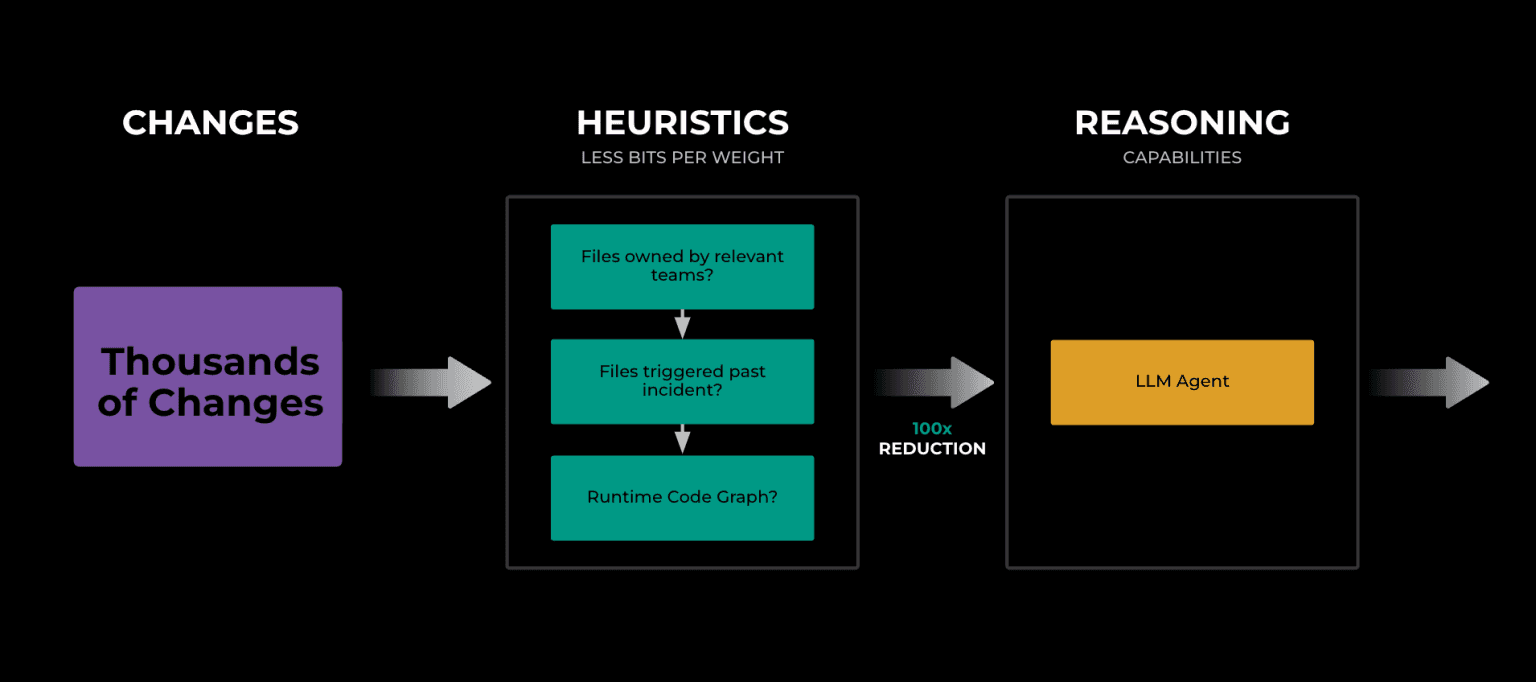
Meta's approach to LLMs for incident response enhances the speed and accuracy of RCA by surfacing likely root causes to engineers at the start of their investigation. To handle the complexity of investigating issues within their massive monolithic codebase, they first use heuristic-based retrieval methods to select a subset of code changes and then use LLM-based ranking to narrow in. The retrieval phase reduces the overwhelming number of potential changes by using heuristics like code ownership, directory structures, and runtime code graphs. Once the search space is narrowed down, only the most relevant changes are passed along for deeper analysis by LLMs.
How Meta scopes down code changes with heuristics and LLMs
The tool fits right into Meta’s existing incident management processes. Engineers investigate issues just as they normally would, but now, the AI results are surfaced at the start of an investigation, automatically pulling in and ranking the most likely causes of the issue in real time. This means they can quickly focus on the most relevant code changes without spending time digging through thousands of possibilities. Instead of replacing the engineers' expertise, the AI acts as a helpful assistant, focusing them in on the most likely causes of the issue sooner.
Fine Tuning Llama 2 7B to Identify Culprit Code Changes
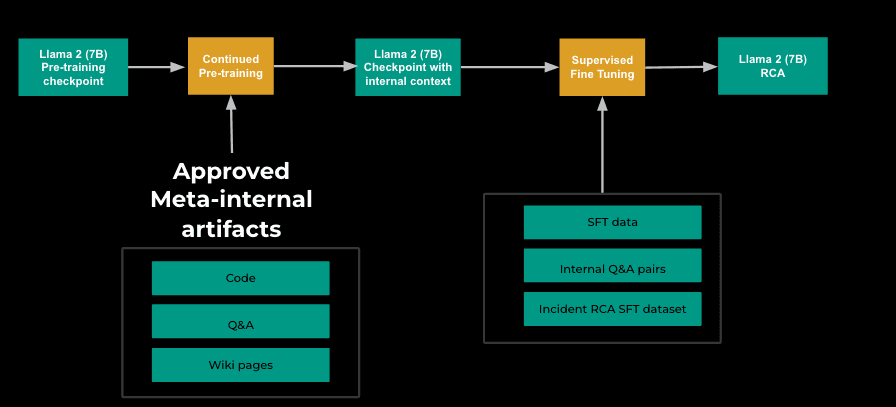
One of the particularly interesting innovations behind Meta's AI incident response is the use of a fine-tuned Llama 2 7B model. The model was tuned specifically for root cause analysis by training it on historical incident investigations, which allowed it to learn from past scenarios where the underlying cause was already known. They used a two-phase approach for fine-tuning: starting with continued pre-training (CPT) and followed by a supervised fine-tuning (SFT) phase. During CPT, the model was exposed to internal Meta artifacts such as wikis, code repositories, and Q&A documents, giving it a contextual foundation. In the SFT phase, Meta mixed the original training data of Llama 2 with its own root cause analysis dataset, which focused on instruction-tuning examples, enabling the model to follow RCA-related prompts effectively.
The fine-tuning process used for Llama 2 7B
The fine-tuning dataset was constructed with the constraints of a real-world investigation in mind. Each example involved 2 to 20 potential code changes, with minimal information known at the time of investigation initiation. By training the model this way, Meta equipped it to handle scenarios where data is scarce, making it more applicable to actual investigations. The fine-tuning process enabled the model to generate ranked lists of potential causes, ordered by relevance. The ranking system is built around log probabilities, where the model evaluates how likely each change is to be the root cause based on historical patterns. This fine-tuning process, combined with the aggregation of new datasets, allows Meta's LLM to significantly improve the accuracy of its root cause predictions, achieving a 42% success rate in identifying the culprit code changes during investigations.
LLM Agents for Incident Response Are Next (Probably)
Meta's use of additional pre-training and fine-tuning on internal documentation and RCA datasets point to another avenue worth exploring: LLM agents for incident response. Agents can actively gather additional relevant context from a larger number of data sources to improve their results. They can also begin to handle more of the incident response process and workflow (find and follow runbooks, measure impact, take mitigation steps, create code changes, write initial post-mortems). Agents are a natural next step, and I'd be surprised if the team isn't already exploring it.
42% Accuracy: Good or Bad?
The biggest question I had when I read the Meta article was how should I interpret the 42% accuracy result? On the surface, this feels like a disappointing result. While there's no great benchmark for human performance, it still seems quite far from what an engineer could achieve. But when you consider that nearly half the time that an investigation began, an engineer had the root cause handed directly to them, it's an incredible result. As long as the engineer has the context and information to quickly rule out incorrect results, this would likely lead to massive improvements in MTTR. It's also an impressive result for the scale of changes that are being shipped at Meta. At a smaller organization, it's likely that finding culprit commits is a much easier task.
Making AI Accessible to All Engineering Teams
The way Meta has integrated AI into their incident response process offers a blueprint for other organizations. By using LLMs to prioritize probable root causes, teams can drastically cut down on investigation time, allowing engineers to jump straight into remediation. AI can help by parsing through logs, tracking recent code changes, and correlating potential issues across different environments. Starting with the investigation
How Parity Can Bring AI to Your Team's Incident Response
Meta is one of the best-resourced engineering teams in the world, and most teams simply don't have armies of researchers with the resources to fine-tune models and experiment with AI technologies. So how does the average team benefit from these insights from Meta? Surely if LLMs can help root cause incidents in one of the most complex infra stacks in the world nearly half the time, they should be helpful for every other engineering organization, right?
That's exactly our goal at Parity. We've built the world's first AI SRE for incident response to bring these benefits to teams everywhere. We use LLM agents to investigate and root cause issues the same way an engineer would. When an alert from PagerDuty or DataDog triggers, Parity's agent begins to investigate the issue, gather context, and presents its findings to the engineer. This means before an on-call engineer has even opened their laptop, Parity has already done an investigation and engineers can move to remediation faster. We're personally pretty excited about Parity's performance, and the fact that Meta is built a similar tool gives us a lot of confidence that other teams can benefit from these solutions!
The Future of Incident Response and AI
The exploration of AI's role in incident response is just getting started, and the potential is clear. Humans aren't great at incident response, and we all hate waking up at 2am to resolve an issue. It's not hard to imagine we'll soon be at super-human performance in this problem space. Underlying improvements in model reasoning ability seem well suited to improving performance in the incident response space (we're particularly excited by the potential of OpenAI's o1). And we believe agents will play an important role in moving accuracy even higher. A world where engineers no longer have to deal with alerts and can get back to building isn't too far away.
There is also massive potential in adjacent areas like cybersecurity incidents. It's not too hard to imagine that LLMs will be used to respond to cyber threats or by security analysts to explore new attack vectors and prevent potential threats (check out our friends from YC over at Asterisk who are working in this space!)
Note: I would like to acknowledge the great work by the team at Meta that worked on this, and I highly recommend reading the original article from Meta Engineering!
In June, Meta released an article titled Leveraging AI for efficient incident response on their engineering blog. In this article, engineers outline how they leveraged large language models to improve Meta's incident response capabilities. The headline metric from this report: Meta was able to use LLMs to successfully root cause incidents with 42% accuracy in their web monorepo. This means that nearly half the time, the mean time to resolution (MTTR) can potentially be reduced from hours to seconds. Seeing one of the largest and most complex engineering organizations in the world use generative AI for incident response so successfully gives us hope that we can bring the same benefit to all engineering teams with Parity. Let's dive into how Meta accomplished these results and what we can learn from it.
Meta's Incident Management at Scale
It can be hard to appreciate the scale and velocity of code changes at a company the size of Meta. They are shipping thousands of changes per day almost entirely within a single monorepo. Meta literally re-engineered Mercurial to keep up with the speed at which their codebase was growing (really fun read and nugget of open source history). At this scale, investigating outages becomes a massive undertaking. "Hey did anyone ship anything recently" in #engineering probably doesn't cut it as a response process.
Meta has invested in sophisticated incident response tools to make the life of on-call engineers easier. All of that tooling is built to solve the same problem any engineer at any organization aims to solve: what's going wrong, why is it going wrong, and how do we fix it. Generative AI has clear potential to improve MTTR and incident management processes across the board, and Meta charts one of the potential paths to doing so.
Meta's Approach to LLMs for Incident Response
Meta's approach to LLMs for incident response enhances the speed and accuracy of RCA by surfacing likely root causes to engineers at the start of their investigation. To handle the complexity of investigating issues within their massive monolithic codebase, they first use heuristic-based retrieval methods to select a subset of code changes and then use LLM-based ranking to narrow in. The retrieval phase reduces the overwhelming number of potential changes by using heuristics like code ownership, directory structures, and runtime code graphs. Once the search space is narrowed down, only the most relevant changes are passed along for deeper analysis by LLMs.
How Meta scopes down code changes with heuristics and LLMs
The tool fits right into Meta’s existing incident management processes. Engineers investigate issues just as they normally would, but now, the AI results are surfaced at the start of an investigation, automatically pulling in and ranking the most likely causes of the issue in real time. This means they can quickly focus on the most relevant code changes without spending time digging through thousands of possibilities. Instead of replacing the engineers' expertise, the AI acts as a helpful assistant, focusing them in on the most likely causes of the issue sooner.
Fine Tuning Llama 2 7B to Identify Culprit Code Changes
One of the particularly interesting innovations behind Meta's AI incident response is the use of a fine-tuned Llama 2 7B model. The model was tuned specifically for root cause analysis by training it on historical incident investigations, which allowed it to learn from past scenarios where the underlying cause was already known. They used a two-phase approach for fine-tuning: starting with continued pre-training (CPT) and followed by a supervised fine-tuning (SFT) phase. During CPT, the model was exposed to internal Meta artifacts such as wikis, code repositories, and Q&A documents, giving it a contextual foundation. In the SFT phase, Meta mixed the original training data of Llama 2 with its own root cause analysis dataset, which focused on instruction-tuning examples, enabling the model to follow RCA-related prompts effectively.
The fine-tuning process used for Llama 2 7B
The fine-tuning dataset was constructed with the constraints of a real-world investigation in mind. Each example involved 2 to 20 potential code changes, with minimal information known at the time of investigation initiation. By training the model this way, Meta equipped it to handle scenarios where data is scarce, making it more applicable to actual investigations. The fine-tuning process enabled the model to generate ranked lists of potential causes, ordered by relevance. The ranking system is built around log probabilities, where the model evaluates how likely each change is to be the root cause based on historical patterns. This fine-tuning process, combined with the aggregation of new datasets, allows Meta's LLM to significantly improve the accuracy of its root cause predictions, achieving a 42% success rate in identifying the culprit code changes during investigations.
LLM Agents for Incident Response Are Next (Probably)
Meta's use of additional pre-training and fine-tuning on internal documentation and RCA datasets point to another avenue worth exploring: LLM agents for incident response. Agents can actively gather additional relevant context from a larger number of data sources to improve their results. They can also begin to handle more of the incident response process and workflow (find and follow runbooks, measure impact, take mitigation steps, create code changes, write initial post-mortems). Agents are a natural next step, and I'd be surprised if the team isn't already exploring it.
42% Accuracy: Good or Bad?
The biggest question I had when I read the Meta article was how should I interpret the 42% accuracy result? On the surface, this feels like a disappointing result. While there's no great benchmark for human performance, it still seems quite far from what an engineer could achieve. But when you consider that nearly half the time that an investigation began, an engineer had the root cause handed directly to them, it's an incredible result. As long as the engineer has the context and information to quickly rule out incorrect results, this would likely lead to massive improvements in MTTR. It's also an impressive result for the scale of changes that are being shipped at Meta. At a smaller organization, it's likely that finding culprit commits is a much easier task.
Making AI Accessible to All Engineering Teams
The way Meta has integrated AI into their incident response process offers a blueprint for other organizations. By using LLMs to prioritize probable root causes, teams can drastically cut down on investigation time, allowing engineers to jump straight into remediation. AI can help by parsing through logs, tracking recent code changes, and correlating potential issues across different environments. Starting with the investigation
How Parity Can Bring AI to Your Team's Incident Response
Meta is one of the best-resourced engineering teams in the world, and most teams simply don't have armies of researchers with the resources to fine-tune models and experiment with AI technologies. So how does the average team benefit from these insights from Meta? Surely if LLMs can help root cause incidents in one of the most complex infra stacks in the world nearly half the time, they should be helpful for every other engineering organization, right?
That's exactly our goal at Parity. We've built the world's first AI SRE for incident response to bring these benefits to teams everywhere. We use LLM agents to investigate and root cause issues the same way an engineer would. When an alert from PagerDuty or DataDog triggers, Parity's agent begins to investigate the issue, gather context, and presents its findings to the engineer. This means before an on-call engineer has even opened their laptop, Parity has already done an investigation and engineers can move to remediation faster. We're personally pretty excited about Parity's performance, and the fact that Meta is built a similar tool gives us a lot of confidence that other teams can benefit from these solutions!
The Future of Incident Response and AI
The exploration of AI's role in incident response is just getting started, and the potential is clear. Humans aren't great at incident response, and we all hate waking up at 2am to resolve an issue. It's not hard to imagine we'll soon be at super-human performance in this problem space. Underlying improvements in model reasoning ability seem well suited to improving performance in the incident response space (we're particularly excited by the potential of OpenAI's o1). And we believe agents will play an important role in moving accuracy even higher. A world where engineers no longer have to deal with alerts and can get back to building isn't too far away.
There is also massive potential in adjacent areas like cybersecurity incidents. It's not too hard to imagine that LLMs will be used to respond to cyber threats or by security analysts to explore new attack vectors and prevent potential threats (check out our friends from YC over at Asterisk who are working in this space!)
Note: I would like to acknowledge the great work by the team at Meta that worked on this, and I highly recommend reading the original article from Meta Engineering!
In June, Meta released an article titled Leveraging AI for efficient incident response on their engineering blog. In this article, engineers outline how they leveraged large language models to improve Meta's incident response capabilities. The headline metric from this report: Meta was able to use LLMs to successfully root cause incidents with 42% accuracy in their web monorepo. This means that nearly half the time, the mean time to resolution (MTTR) can potentially be reduced from hours to seconds. Seeing one of the largest and most complex engineering organizations in the world use generative AI for incident response so successfully gives us hope that we can bring the same benefit to all engineering teams with Parity. Let's dive into how Meta accomplished these results and what we can learn from it.
Meta's Incident Management at Scale
It can be hard to appreciate the scale and velocity of code changes at a company the size of Meta. They are shipping thousands of changes per day almost entirely within a single monorepo. Meta literally re-engineered Mercurial to keep up with the speed at which their codebase was growing (really fun read and nugget of open source history). At this scale, investigating outages becomes a massive undertaking. "Hey did anyone ship anything recently" in #engineering probably doesn't cut it as a response process.
Meta has invested in sophisticated incident response tools to make the life of on-call engineers easier. All of that tooling is built to solve the same problem any engineer at any organization aims to solve: what's going wrong, why is it going wrong, and how do we fix it. Generative AI has clear potential to improve MTTR and incident management processes across the board, and Meta charts one of the potential paths to doing so.
Meta's Approach to LLMs for Incident Response
Meta's approach to LLMs for incident response enhances the speed and accuracy of RCA by surfacing likely root causes to engineers at the start of their investigation. To handle the complexity of investigating issues within their massive monolithic codebase, they first use heuristic-based retrieval methods to select a subset of code changes and then use LLM-based ranking to narrow in. The retrieval phase reduces the overwhelming number of potential changes by using heuristics like code ownership, directory structures, and runtime code graphs. Once the search space is narrowed down, only the most relevant changes are passed along for deeper analysis by LLMs.
How Meta scopes down code changes with heuristics and LLMs
The tool fits right into Meta’s existing incident management processes. Engineers investigate issues just as they normally would, but now, the AI results are surfaced at the start of an investigation, automatically pulling in and ranking the most likely causes of the issue in real time. This means they can quickly focus on the most relevant code changes without spending time digging through thousands of possibilities. Instead of replacing the engineers' expertise, the AI acts as a helpful assistant, focusing them in on the most likely causes of the issue sooner.
Fine Tuning Llama 2 7B to Identify Culprit Code Changes
One of the particularly interesting innovations behind Meta's AI incident response is the use of a fine-tuned Llama 2 7B model. The model was tuned specifically for root cause analysis by training it on historical incident investigations, which allowed it to learn from past scenarios where the underlying cause was already known. They used a two-phase approach for fine-tuning: starting with continued pre-training (CPT) and followed by a supervised fine-tuning (SFT) phase. During CPT, the model was exposed to internal Meta artifacts such as wikis, code repositories, and Q&A documents, giving it a contextual foundation. In the SFT phase, Meta mixed the original training data of Llama 2 with its own root cause analysis dataset, which focused on instruction-tuning examples, enabling the model to follow RCA-related prompts effectively.
The fine-tuning process used for Llama 2 7B
The fine-tuning dataset was constructed with the constraints of a real-world investigation in mind. Each example involved 2 to 20 potential code changes, with minimal information known at the time of investigation initiation. By training the model this way, Meta equipped it to handle scenarios where data is scarce, making it more applicable to actual investigations. The fine-tuning process enabled the model to generate ranked lists of potential causes, ordered by relevance. The ranking system is built around log probabilities, where the model evaluates how likely each change is to be the root cause based on historical patterns. This fine-tuning process, combined with the aggregation of new datasets, allows Meta's LLM to significantly improve the accuracy of its root cause predictions, achieving a 42% success rate in identifying the culprit code changes during investigations.
LLM Agents for Incident Response Are Next (Probably)
Meta's use of additional pre-training and fine-tuning on internal documentation and RCA datasets point to another avenue worth exploring: LLM agents for incident response. Agents can actively gather additional relevant context from a larger number of data sources to improve their results. They can also begin to handle more of the incident response process and workflow (find and follow runbooks, measure impact, take mitigation steps, create code changes, write initial post-mortems). Agents are a natural next step, and I'd be surprised if the team isn't already exploring it.
42% Accuracy: Good or Bad?
The biggest question I had when I read the Meta article was how should I interpret the 42% accuracy result? On the surface, this feels like a disappointing result. While there's no great benchmark for human performance, it still seems quite far from what an engineer could achieve. But when you consider that nearly half the time that an investigation began, an engineer had the root cause handed directly to them, it's an incredible result. As long as the engineer has the context and information to quickly rule out incorrect results, this would likely lead to massive improvements in MTTR. It's also an impressive result for the scale of changes that are being shipped at Meta. At a smaller organization, it's likely that finding culprit commits is a much easier task.
Making AI Accessible to All Engineering Teams
The way Meta has integrated AI into their incident response process offers a blueprint for other organizations. By using LLMs to prioritize probable root causes, teams can drastically cut down on investigation time, allowing engineers to jump straight into remediation. AI can help by parsing through logs, tracking recent code changes, and correlating potential issues across different environments. Starting with the investigation
How Parity Can Bring AI to Your Team's Incident Response
Meta is one of the best-resourced engineering teams in the world, and most teams simply don't have armies of researchers with the resources to fine-tune models and experiment with AI technologies. So how does the average team benefit from these insights from Meta? Surely if LLMs can help root cause incidents in one of the most complex infra stacks in the world nearly half the time, they should be helpful for every other engineering organization, right?
That's exactly our goal at Parity. We've built the world's first AI SRE for incident response to bring these benefits to teams everywhere. We use LLM agents to investigate and root cause issues the same way an engineer would. When an alert from PagerDuty or DataDog triggers, Parity's agent begins to investigate the issue, gather context, and presents its findings to the engineer. This means before an on-call engineer has even opened their laptop, Parity has already done an investigation and engineers can move to remediation faster. We're personally pretty excited about Parity's performance, and the fact that Meta is built a similar tool gives us a lot of confidence that other teams can benefit from these solutions!
The Future of Incident Response and AI
The exploration of AI's role in incident response is just getting started, and the potential is clear. Humans aren't great at incident response, and we all hate waking up at 2am to resolve an issue. It's not hard to imagine we'll soon be at super-human performance in this problem space. Underlying improvements in model reasoning ability seem well suited to improving performance in the incident response space (we're particularly excited by the potential of OpenAI's o1). And we believe agents will play an important role in moving accuracy even higher. A world where engineers no longer have to deal with alerts and can get back to building isn't too far away.
There is also massive potential in adjacent areas like cybersecurity incidents. It's not too hard to imagine that LLMs will be used to respond to cyber threats or by security analysts to explore new attack vectors and prevent potential threats (check out our friends from YC over at Asterisk who are working in this space!)
Note: I would like to acknowledge the great work by the team at Meta that worked on this, and I highly recommend reading the original article from Meta Engineering!
Share
HN
Revolutionize Your Incident Response
Revolutionize Your Incident Response
Transform your on-call with Parity's AI SRE. Parity works with your team to resolve incidents in seconds, not hours.
Transform your on-call with Parity's AI SRE. Parity works with your team to resolve incidents in seconds, not hours.

You may also like
You may also like

Wilson Spearman
Co-founder
Mar 20, 2025
You Spend Millions on Reliability. So why Does Everything Still Break?
Reliability's Expensive and Everything Still Breaks. Why?
Wilson Spearman
Co-founder
Mar 20, 2025
You Spend Millions on Reliability. So why Does Everything Still Break?
Reliability's Expensive and Everything Still Breaks. Why?

Wilson Spearman
Co-founder
Jan 31, 2025
Is the Helm Killer Finally Here?
AWS, Google Cloud, and Microsoft unveil kro, a k8s-native, cloud-agnostic package manager
Wilson Spearman
Co-founder
Jan 31, 2025
Is the Helm Killer Finally Here?
AWS, Google Cloud, and Microsoft unveil kro, a k8s-native, cloud-agnostic package manager
